5 t-tests revisited
In this chapter we look at an example with one categorical explanatory variable which has two groups (or levels). We first use the familiar t.test() then use its output to help us understand the output of lm(). We will also make predictions from the model and report on our results.
5.1 Introduction to the example
Some plant biotechnologists developed a genetically modified line of Cannabis sativa to increase its omega 3 fatty acids content. They grew 50 wild type and fifty modified plants to maturity, collect the seeds and measure the amount of omega 3 fatty acids (in arbitrary units). The data are in csativa.txt. They want to know if the wild type and modified plants differ significantly in their omega 3 fatty acid content.
| omega | plant |
|---|---|
| 48.5 | modif |
| 43.6 | modif |
| 51.2 | modif |
| 56.4 | modif |
| 56.0 | modif |
| 58.7 | modif |
| 39.1 | modif |
| 48.8 | modif |
| 55.5 | modif |
| 44.6 | modif |
| 46.5 | modif |
| 41.5 | modif |
| 40.8 | modif |
| 45.1 | modif |
| 46.1 | modif |
| 39.4 | modif |
| 47.2 | modif |
| 48.0 | modif |
| 50.7 | modif |
| 48.2 | modif |
| 48.4 | modif |
| 48.1 | modif |
| 56.7 | modif |
| 49.6 | modif |
| 49.1 | modif |
| 47.4 | modif |
| 59.9 | modif |
| 54.3 | modif |
| 61.9 | modif |
| 46.7 | modif |
| 58.3 | modif |
| 41.9 | modif |
| 52.7 | modif |
| 54.5 | modif |
| 59.6 | modif |
| 49.6 | modif |
| 47.4 | modif |
| 53.4 | modif |
| 48.1 | modif |
| 53.8 | modif |
| 42.8 | modif |
| 45.8 | modif |
| 42.4 | modif |
| 48.2 | modif |
| 49.8 | modif |
| 50.1 | modif |
| 48.4 | modif |
| 61.0 | modif |
| 41.3 | modif |
| 46.3 | modif |
| 58.5 | wild |
| 55.5 | wild |
| 58.7 | wild |
| 67.7 | wild |
| 41.4 | wild |
| 48.0 | wild |
| 64.5 | wild |
| 52.2 | wild |
| 54.2 | wild |
| 40.5 | wild |
| 59.1 | wild |
| 68.5 | wild |
| 47.9 | wild |
| 60.5 | wild |
| 63.0 | wild |
| 57.5 | wild |
| 58.0 | wild |
| 70.2 | wild |
| 67.1 | wild |
| 52.7 | wild |
| 60.2 | wild |
| 42.5 | wild |
| 60.2 | wild |
| 53.8 | wild |
| 45.4 | wild |
| 53.2 | wild |
| 63.3 | wild |
| 45.3 | wild |
| 65.3 | wild |
| 61.9 | wild |
| 49.2 | wild |
| 73.3 | wild |
| 70.3 | wild |
| 56.3 | wild |
| 56.0 | wild |
| 53.5 | wild |
| 63.6 | wild |
| 45.9 | wild |
| 54.5 | wild |
| 54.6 | wild |
| 50.9 | wild |
| 58.2 | wild |
| 54.5 | wild |
| 56.6 | wild |
| 54.1 | wild |
| 53.5 | wild |
| 56.9 | wild |
| 46.0 | wild |
| 50.0 | wild |
| 65.7 | wild |
There are 2 variables.
plant is the explanatory variable; it is categorical with 2 levels, modif and wild.
omega, a continuous variable, is the response.
We again use the read_table() function to import the data and visualise it with ggplot()
csativa <- read_table("data-raw/csativa.txt")A quick plot of the data:
ggplot(data = csativa, aes(x = plant, y = omega)) +
geom_violin()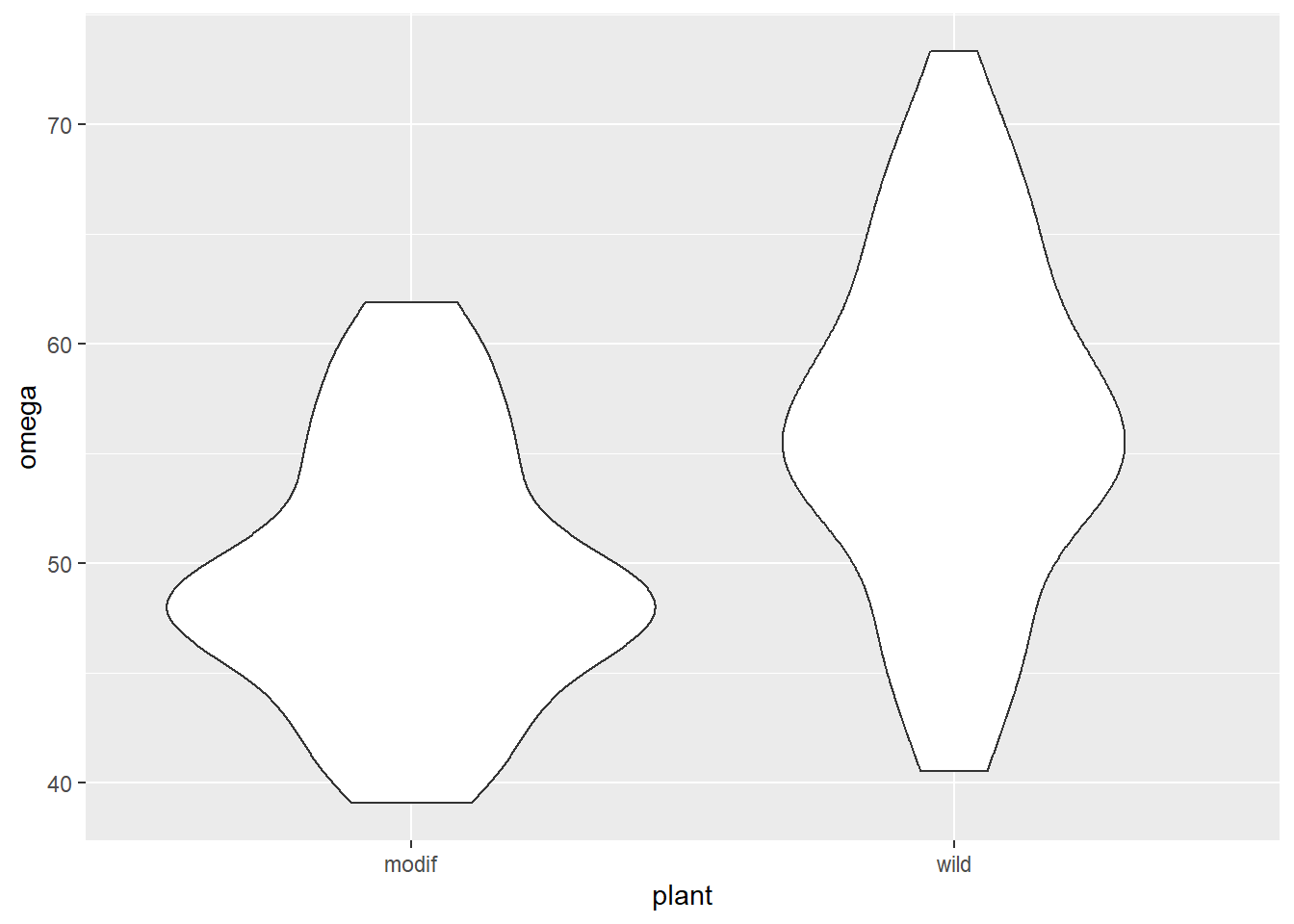
Violin plots are a useful way to show the distribution of data in each group but not the only way. One alternative is geom_boxplot().
The modified plants have a lower mean omega 3 content than the wild type plants. The modification appears not to be successful! In fact, it may have significantly lowered the omega 3 content!
Let’s create a summary of the data that will be useful for plotting later:
csativa_summary <- csativa %>%
group_by(plant) %>%
summarise(mean = mean(omega),
std = sd(omega),
n = length(omega),
se = std/sqrt(n))| plant | mean | std | n | se |
|---|---|---|---|---|
| modif | 49.5 | 5.82 | 50 | 0.82 |
| wild | 56.4 | 7.85 | 50 | 1.11 |
Our summary confirms what we see in the plot.
Statistical comparison of the two means can be done with either the t.test() or lm() functions; these are exactly equivalent but present the results differently. We will use our understanding of applying and interpreting t.test() to develop our understanding of lm() output
5.2 t.test() output reminder
We can apply a two-sample t-test with:
t.test(data = csativa, omega ~ plant, var.equal = TRUE)
#
# Two Sample t-test
#
# data: omega by plant
# t = -5, df = 98, p-value = 0.000002
# alternative hypothesis: true difference in means between group modif and group wild is not equal to 0
# 95 percent confidence interval:
# -9.69 -4.21
# sample estimates:
# mean in group modif mean in group wild
# 49.5 56.4The two groups means are given in the section labelled sample estimates and the test of whether they differ significantly is given in the fourth line (beginning t = -5, df = ...). We conclude the mean omega 3 content of the modified plants (49.465 units) is significantly lower than that of the wild type plants (\(t\) = 5.029, \(d.f.\) = 98, \(p\) < 0.001).
The line under 95 percent confidence intervalgives the confidence limits on the difference between the two means.
The sign on the \(t\) value and the confidence limits, and the order in which the sample estimates are given is determined by R’s alphabetical ordering of the groups. As “modif” comes before “wild” in the alphabet, “modif” is the first group. The statistical test is: the modified plant mean \(-\) the wild type mean.
This ordering is arbitrary and has has no impact on our conclusions. If the wild type plants been labelled “control” so that “modif” would be the second group, our output would look like this:
# Two Sample t-test
#
# data: omega by plant
# t = 5.0289, df = 98, p-value = 2.231e-06
# alternative hypothesis: true difference in means is not equal to 0
# 95 percent confidence interval:
# 4.205372 9.687828
# sample estimates:
# mean in group control mean in group modif
# 56.4118 49.4652
# Our conclusion would remain the same: 49.465 is significantly lower than 56.412.
t.test() output: the estimates are the two group means and the p-value is for a test on the difference between them.
5.3 t-tests as linear models
The equation for a t-test is just as it was for equation (2.1): \[\begin{equation} E(y_{i})=\beta_{0}+\beta_{1}X1_{i} \tag{5.1} \end{equation}\]
Remember, in a single linear regression \(\beta_{0}\), the intercept, is the value of the response when the numerical explanatory variable is zero. So what does this mean when the explanatory variable is categorical?
It means the intercept is the value of the response when the categorical explanatory is at its “lowest” level where the “lowest” level is the group which comes first alphabetically.
\(X1_{i}\) is an indicator variable that takes the value of 0 or 1 and indicates whether the \(i\)th value was from one group or not. Such variables are known as dummy explanatory variables. They are dummy in the sense that they are numerical substitutes for the categorical variable whose ‘real’ values are the names of the categories.
You can think of \(X1_{i}\) as toggling on and off the \(\beta_{1}\) effect:
- If it has a value of 0 for a data point it means that \(\beta_{1}\) will not impact the response. The response will be will be \(\beta_{0}\).
- If it has a value 1 then \(\beta_{1}\) will change the response to \(\beta_{0}\) + \(\beta_{1}\)
\(\beta_{1}\) is thus the difference between the group means.
A graphical representation of the terms in a linear model when the explanatory variable is categorical with two groups is given in Figure 5.1.

Figure 5.1: A linear model when the explanatory variable is categorical with two groups annotated with the terms used in linear modelling. The measured response values are in pink, the predictions are in green, and the differences between these, known as the residuals, are in blue. The estimated model parameters are indicated: \(\beta_{0}\) is the mean of group A and \(\beta_{1}\) is what has to be added to \(\beta_{0}\) to get the mean of group B. Compare to Figure 2.2.
5.4 Applying and interpreting lm()
The lm() function is applied to this example as follows:
mod <- lm(data = csativa, omega ~ plant)This can be read as: fit a linear of model of omega content explained by plant type. Notice that the model formula is the same in both the t.test() and the lm() functions.
Printing mod to the console gives us the estimated model parameters (coefficients):
mod
#
# Call:
# lm(formula = omega ~ plant, data = csativa)
#
# Coefficients:
# (Intercept) plantwild
# 49.47 6.95The first group of plant is modif so \(\beta_{0}\) is the mean of the modified plants. \(\beta_{1}\) is the coefficient labelled plantwild. In R, the coefficients are consistently named like this: variable name followed by the value without spaces. It means when the variable plant takes the value wild, \(\beta_{1}\) must be added to \(\beta_{0}\)
Thus, the mean omega 3 in the modified plants is 49.465 units and that in the wild type plants is 49.465 + 6.947 = 56.412 units.
More information including statistical tests of the model and its parameters is obtained by using summary():
summary(mod)
#
# Call:
# lm(formula = omega ~ plant, data = csativa)
#
# Residuals:
# Min 1Q Median 3Q Max
# -15.872 -3.703 -0.964 4.460 16.918
#
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) 49.465 0.977 50.64 < 0.0000000000000002 ***
# plantwild 6.947 1.381 5.03 0.0000022 ***
# ---
# Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#
# Residual standard error: 6.91 on 98 degrees of freedom
# Multiple R-squared: 0.205, Adjusted R-squared: 0.197
# F-statistic: 25.3 on 1 and 98 DF, p-value: 0.00000223The Coefficients table gives the estimated \(\beta_{0}\) and \(\beta_{1}\) again but along with their standard errors and tests of whether the estimates differ from zero. The estimated mean of the modified plants is 49.465 \(\pm\) 0.977 and this differs significantly from zero (\(p\) < 0.001). The estimated difference between the modified and wild type plants is 6.947 \(\pm\) 1.381 and also differs significantly from zero (\(p\) < 0.001). The fact that this value is positive tells us that the wild type plants have a higher mean.
The proportion of the variance in the omega which is explained by the model is 0.205 and this is a significant proportion of that variance (\(p\) < 0.001).
As was true for single linear regression, the p-value for the model and the p-value for the difference between the means are the same because there is only one parameter in the model after the intercept.
Replacing the terms shown in Figure 5.1 with the values in this example gives us 5.2.

Figure 5.2: The annotated model with the values from the Omega 3 content of Cannabis sativa example. The measured response values are in pink, the predictions are in green, and the residuals, are in blue. One example of a measured value, a predicted value and the residual is shown for a wild type individual. The estimated model parameters are indicated: \(\beta_{0}\), the mean of the modified plants, is 49.465 and \(\beta_{1}\) is 6.947. Thus the mean of wildtype plants is 49.465 + 6.947 = 56.412 units. Compare to Figure 5.1.
5.5 Getting predictions from the model
We already have the predictions for all possible values of the explanatory variable because there are only two!
However the code for using predict is included here because it will make it easier to understand more complex examples later. We need to create a dataframe of values for which we want predictions and pass it as an argument to the predict() function.
To create a dataframe with one column of Plant values:
predict_for <- data.frame(plant = c("modif", "wild"))Remember! The variable and its values have to exactly match those in the model.
The to get the predicted omega content for the two plant types:
predict_for$pred <- predict(mod, newdata = predict_for)
glimpse(predict_for)
# Rows: 2
# Columns: 2
# $ plant <chr> "modif", "wild"
# $ pred <dbl> 49.5, 56.45.6 Checking assumptions
The two assumptions of the model can be checked using diagnostic plots. The Q-Q plot is obtained with:
plot(mod, which = 2)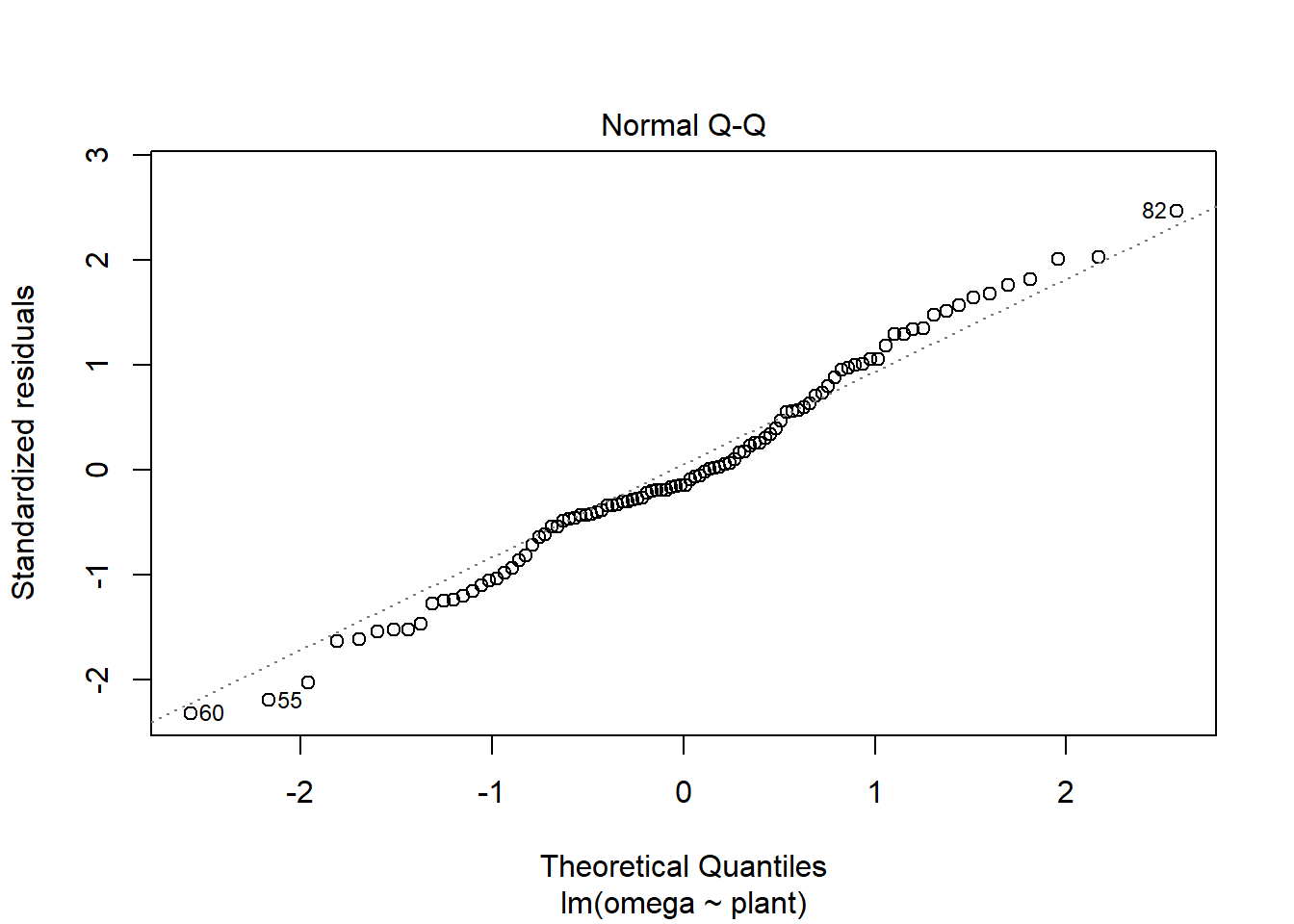
The residual seem to be normally distributed.
Let’s look at the Residuals vs Fitted plot:
plot(mod, which = 1)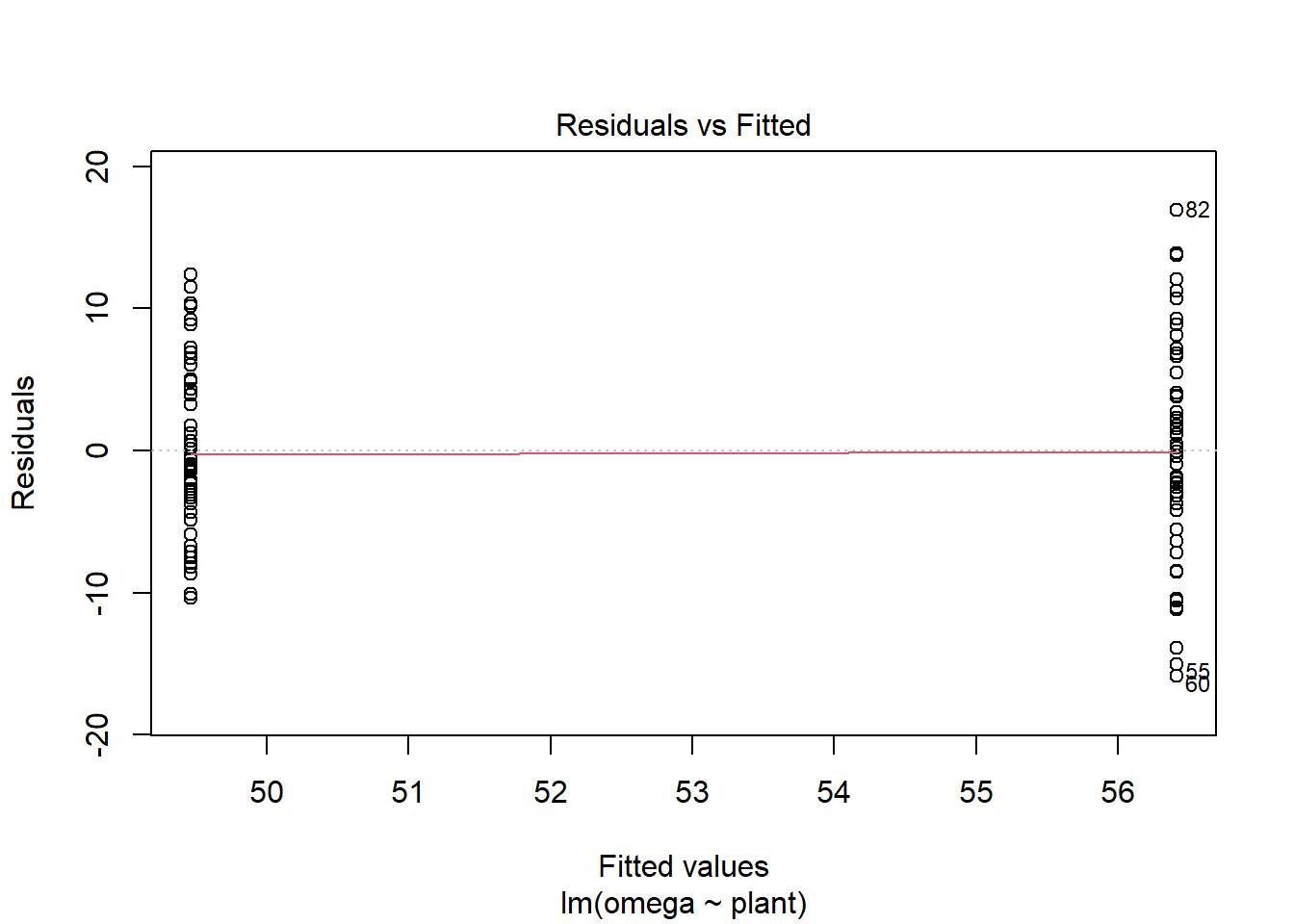
We get these two columns of points because the explanatory variable, plant, is categorical so the fitted - or predicted - values are just two means. In my view, the variance looks higher in the group with the higher mean (on the right).
5.7 Creating a figure
#summarise the data
ggplot() +
geom_jitter(data = csativa,
aes(x = plant, y = omega),
width = 0.25, colour = "grey") +
geom_errorbar(data = csativa_summary,
aes(x = plant,
ymin = mean,
ymax = mean),
width = .3) +
geom_errorbar(data = csativa_summary,
aes(x = plant,
ymin = mean - se,
ymax = mean + se),
width = .5) +
geom_segment(aes(x = 1, y = 75, xend = 2, yend = 75),
size = 1) +
geom_segment(aes(x = 1, y = 75, xend = 1, yend = 73),
size = 1) +
geom_segment(aes(x = 2, y = 75, xend = 2, yend = 73),
size = 1) +
annotate("text", x = 1.5, y = 77, label = "***", size = 6) +
scale_x_discrete(labels = c("Modified", "Wild Type"),
name = "Plant type") +
scale_y_continuous(name = "Amount of Omega 3 (units)",
expand = c(0, 0),
limits = c(0, 90)) +
theme_classic()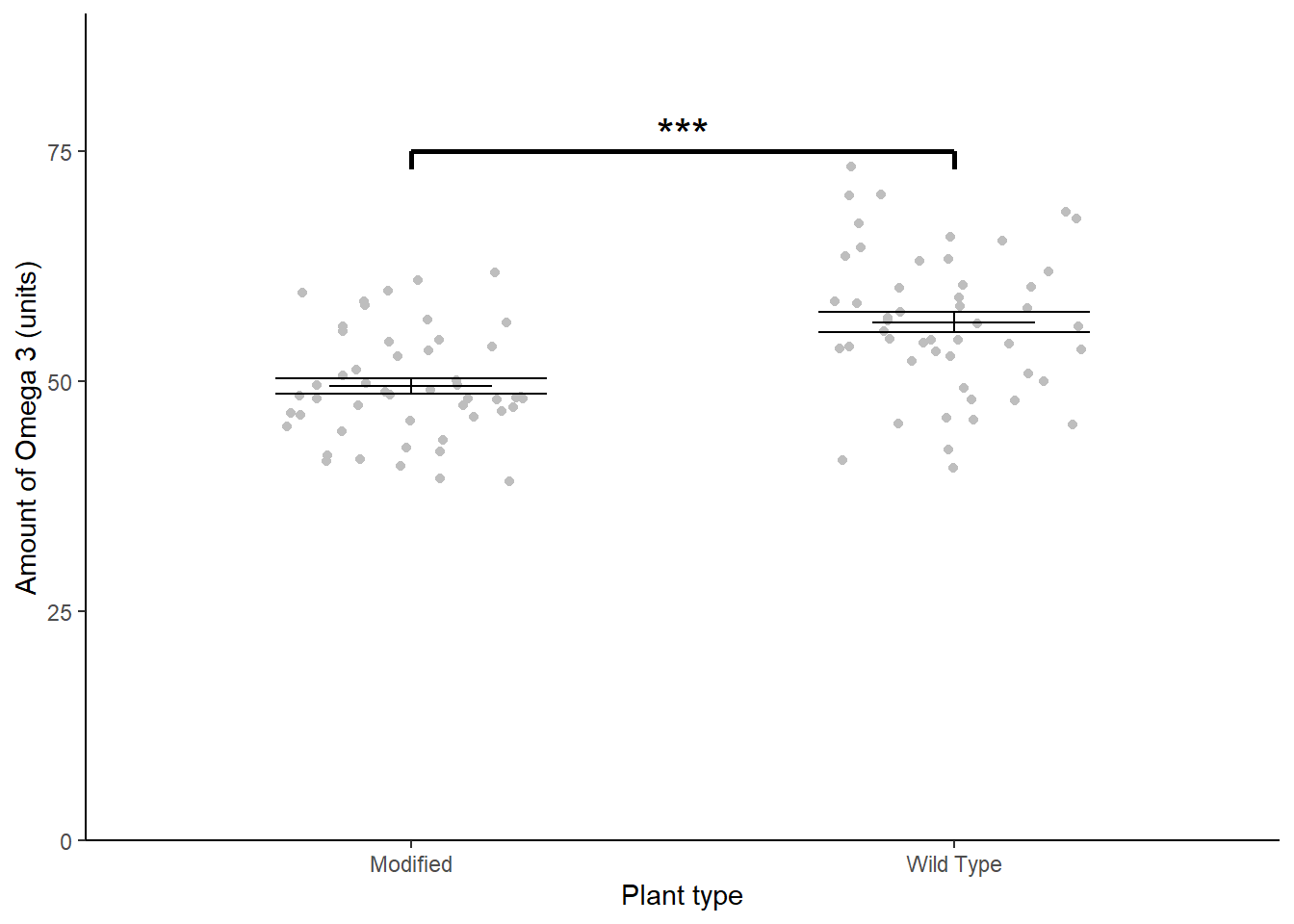
5.8 Reporting the results
The genetic modification was unsuccessful with wild type plants (\(\bar{x} \pm s.e.\): 56.412 \(\pm\) 1.11 units) have significantly higher omega 3 than modified plants(49.465 \(\pm\) 0.823 units) (\(t\) = 5.029; \(d.f.\) = 98; \(p\) < 0.001). See figure 5.3.
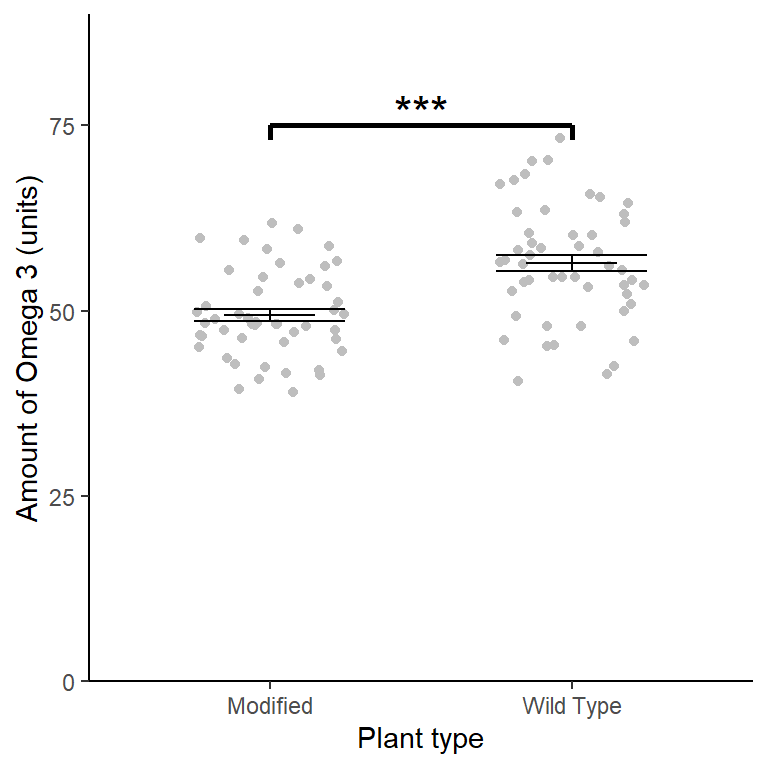
Figure 5.3: Mean Omega 3 content of wild type and genetically modified Cannabis sativa. Error bars are \(\pm 1 S.E.\). *** significant difference at the \(p < 0.001\) level.