5 Ideas about data
Complete
You are reading a live document. This page is compete but suggestions for improvements are welcome. Follow the link to ‘Make a suggestion’ to suggest improvements.
5.1 Introduction
This chapter introduces some key ideas about data. Data consists of:
- Variables — the properties or characteristics that we measure or record, and
- Observations — the individual cases or items that those variables describe.
A helpful and common way to organise data is in a table, where each column represents a variable and each row represents one observation. Every value in a row related to a single observation such as a person, plant, or sample. We call data in this format “tidy”.
We can describe variables in two main ways:
By their role in the analysis, that is, whether they are independent (explanatory) or dependent (response) variables.
By the type of values they take and how often those values occur.
The second aspect — what kinds of values a variable can have and how common each one is — is called the variable’s distribution. The way we summarise, visualise, and analyse a variable depends on both its role and its distribution.
5.2 Roles of variables in analysis
When we do research, we typically have variables that we choose or set and variables that we measure. The variables we choose or set are called independent or explanatory variables. The variables we measure are called dependent or response variables. For example, we might measure the concentration of enzymes and hormones in blood samples of individuals with different genotypes. The genotype acts as the explanatory variable and the blood measurements are response. We would be interested in whether the blood measures differ between genotypes.
5.3 Distributions
Any variable has a distribution which describes the values the variable can take and the chance of them occurring. The distribution is a function (relationship) which captures how the values are mapped to the probability of them occurring. A distribution has a general type, given by the function and is further tuned by the parameters in the function. For example, variables like height, length, concentration, mass and intensity follow a normal distribution also know as the bell-shaped curve so that they look similar. However, they have different means and standard deviations. The mean and the standard deviation are the parameters of the normal distribution.
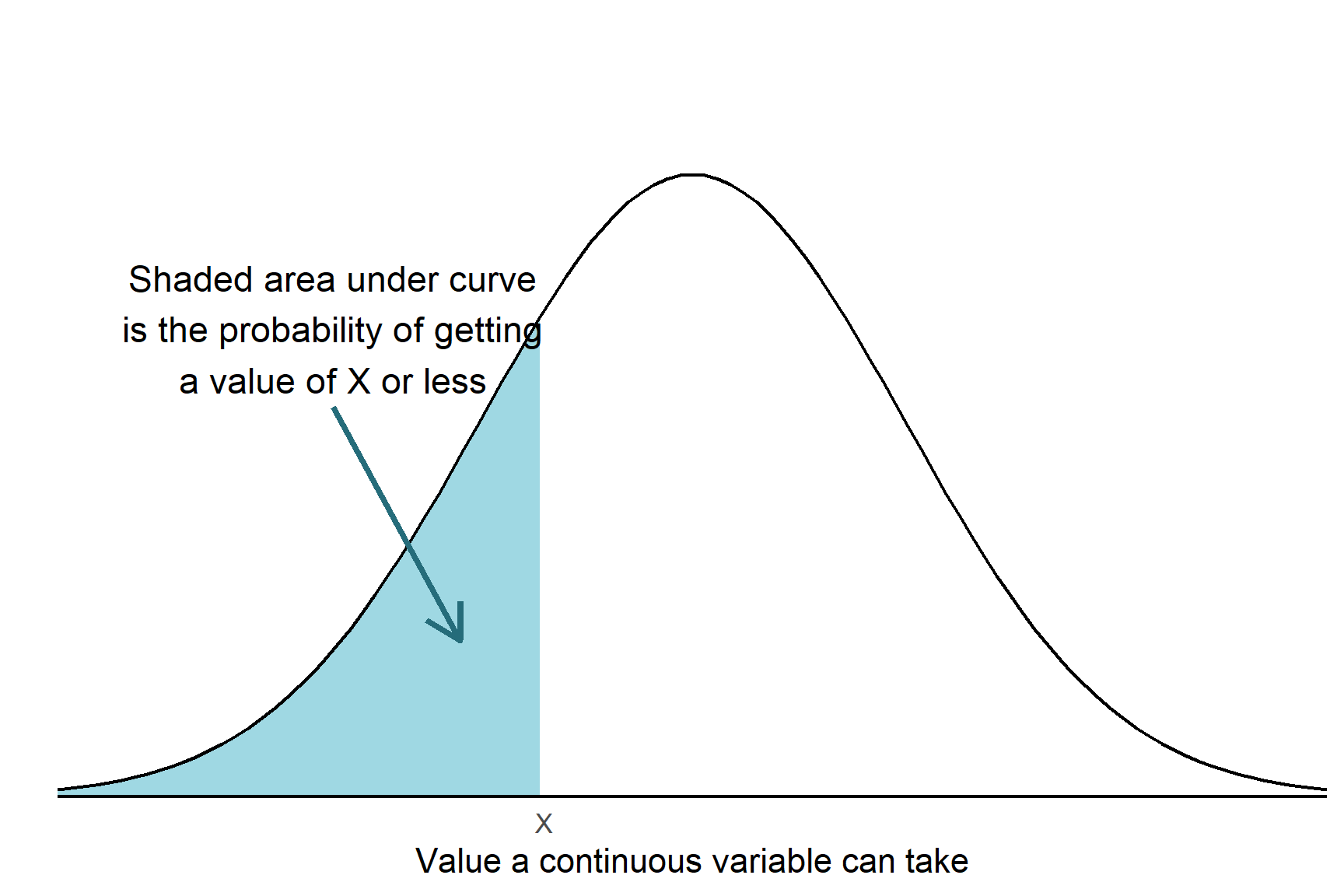
An important distinction is between discrete and continuous types of data. Continuous variables are measurements that can take any value in their range. Because there an infinite number of possible values within within the range, the probability of a continuous variable taking exactly one specific value is zero. Instead, we talk about the probability that the value is less than a particular value, greater than a particular value or between two values. For example, we might say the probability a person’s height is greater than 170cm is 0.3 (Figure 5.1). In contrast, discrete variables can take only specific values often counts or categories. For example, the number of leaves on a plant or the number of times a gene is expressed. In this case, it’s meaningful to talk about the probability of a single value. Each possible value has its own individual probability, and the sum of all those probabilities equals 1 (Figure 5.2).
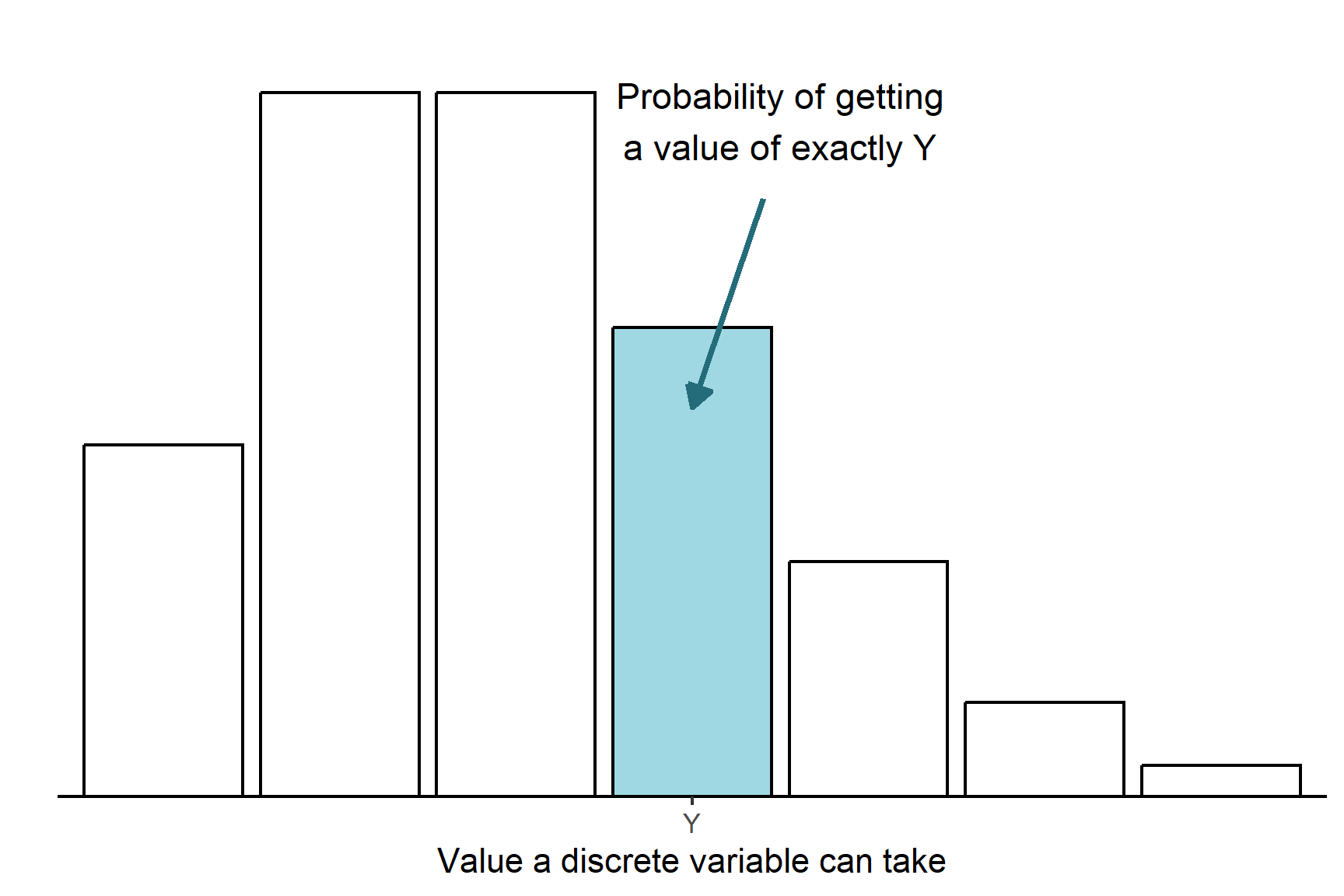
This difference between continuous and discrete variables affects how we analyse and visualise data. Discrete data is often shown using bar plots and summarised with modes of medians, while continuous data is represented using histograms or density plots and summarised with means and standard deviations.
5.4 Summarising data
We summarise data by giving a measure of central tendency and a measure of dispersion. A measure of central tendency is a single value that represents the middle or centre of a variable’s distribution. The three most common measures are:
the mean, or more accurately, the arithmetic mean, \(\bar{x} = \frac{\sum{x}}{n}\)
the median: the middle value for a variable with values arranged in order of magnitude
the mode: the most frequent value in the variable.
Measures of dispersion describe the spread of values around the centre and indicate how much variability there is in the variable. The most common measures of dispersion are:
the range: the difference between the maximum value and the minimum value in a variable
the interquartile range: two values, the first quartile and the third quartile. The first quartile is half way between the median value and the lowest value when the values are arranged in order and the third quartile is halfway between the median value and the highest value
the variance: the average of the squared differences between each value and the variable’s mean, \(s^2 = \frac{(\sum{x - \bar{x})^2}}{n - 1}\)
the standard deviation: the square root of the variance.
5.5 Discrete data
Discrete variables can take only specific values and can be categories, like genotype, or counts, like the number of petals.
5.5.1 Categories: Nominal and Ordinal
Categorical data can be nominal or ordinal depending on whether the categories are are ordered. Nominal variables have no particular order, for example, the eye colour of Drosophila or the species of bird. When summarising data on bird species, it wouldn’t matter in what order the information was given or plotted. Ordinal variables have an order. The Likert scale (Likert 1932) used in questionnaires is one example. The possible responses are Strongly agree, Agree, Disagree and Strongly disagree; these have an order that you would use when plotting them (Figure 5.3).
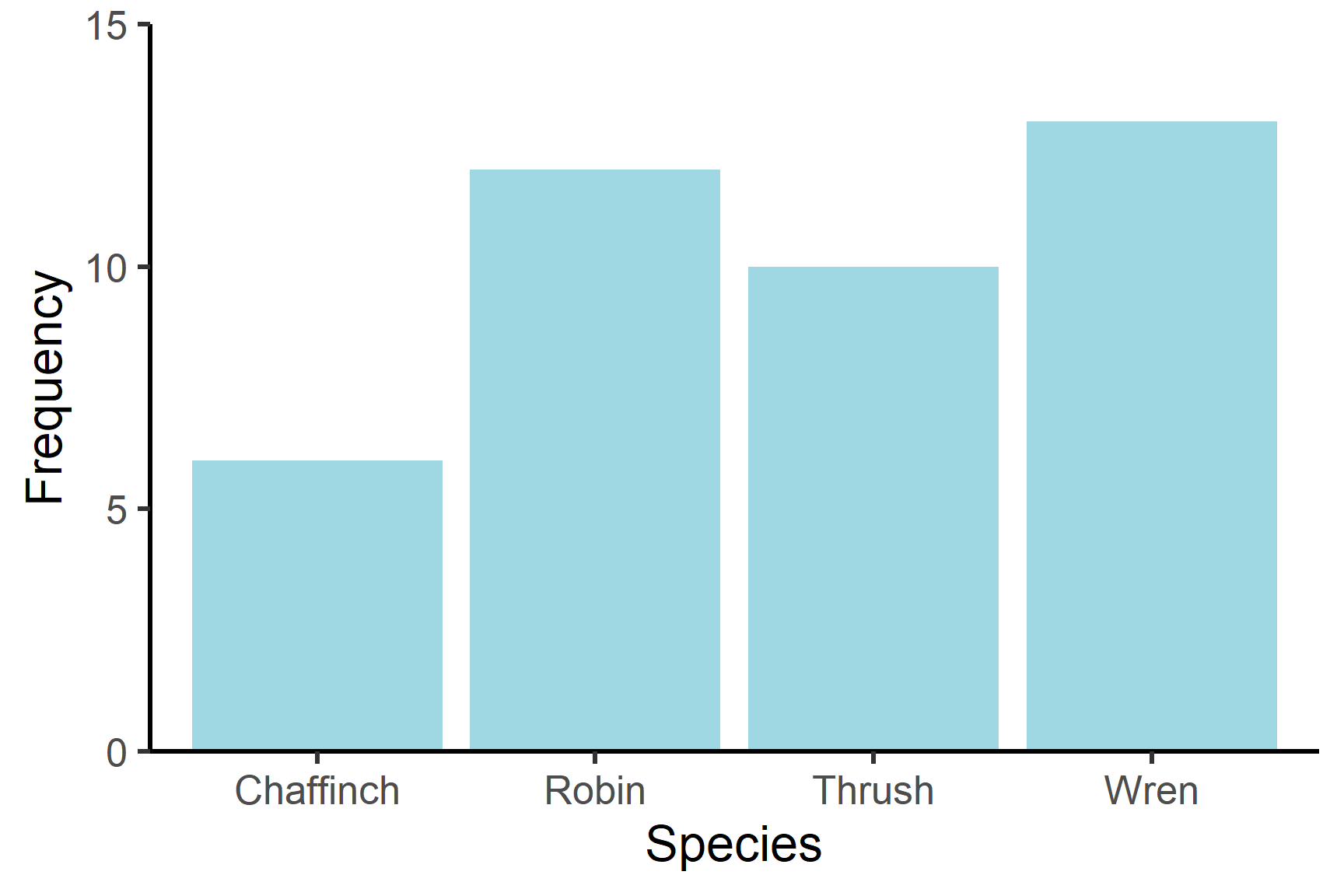

The most appropriate way to summarise nominal or ordinal data is to report the mode (most frequent value) or tabulate the number of each value (Table 5.1).
| Response | Frequency |
|---|---|
| Strongly agree | 10 |
| Agree | 14 |
| Disagree | 6 |
| Strongly disagree | 2 |
5.5.2 Counts
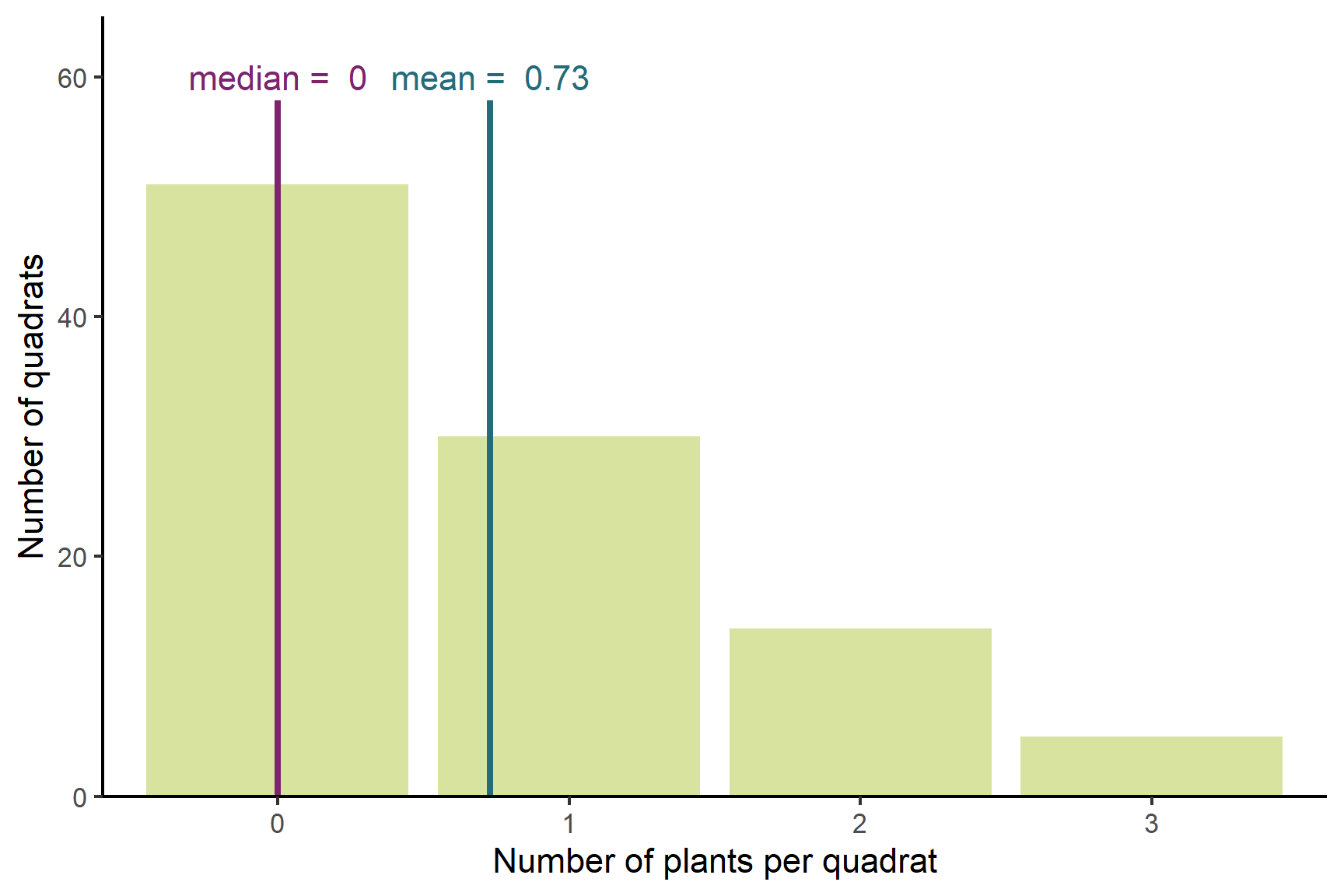
Counts are one of the most common data types. They are quantitative but discrete because they can take only specific values. Counts tend to follow a distribution called the Poisson distribution meaning that there is an expected number of zeros, ones and twos etc that appear. This is true no matter what you count. The distribution of counts is not symmetrical when the average count is low. For example, the number of groundsel plants in one hundred 1 metre x 1 metre square quadrats1 is likely in the range of 0 to 3 plants per quadrat. This distribution is skewed to the right, meaning it has a tail to the right. A mean is not usually the best way to summarise a set of counts because it is dragged up by the few quadrats with more than 2 plants (Figure 5.4). Instead, the median better represents the middle of the distribution. The median is the middle value when the values are arranged in order. The interquartile range (IQR) indicates the spread in the data. The lower quartile is half way between the lowest value and the middle value and the upper quartile is half way between the middle value and the highest value.
5.6 Continuous data
Continuous variables are measurements that can take any value in their range so there are an infinite number of possible values. The values have decimal places. Variables like the length and mass of an organism, the volume and optical density of a solution, or the colour intensity of an image are continuous. Many response variables are continuous but continuous variables can also be explanatory. A large number of continuous variables follow the normal distribution.
5.6.1 The normal distribution
For example, a variable like human height has values with decimal places which follow a normal distribution also known as the Gaussian distribution or the bell-shaped curve. Values of 1.65 metres occur more often than values of 2 metres and values of 3 metres never occur (Figure 5.5).
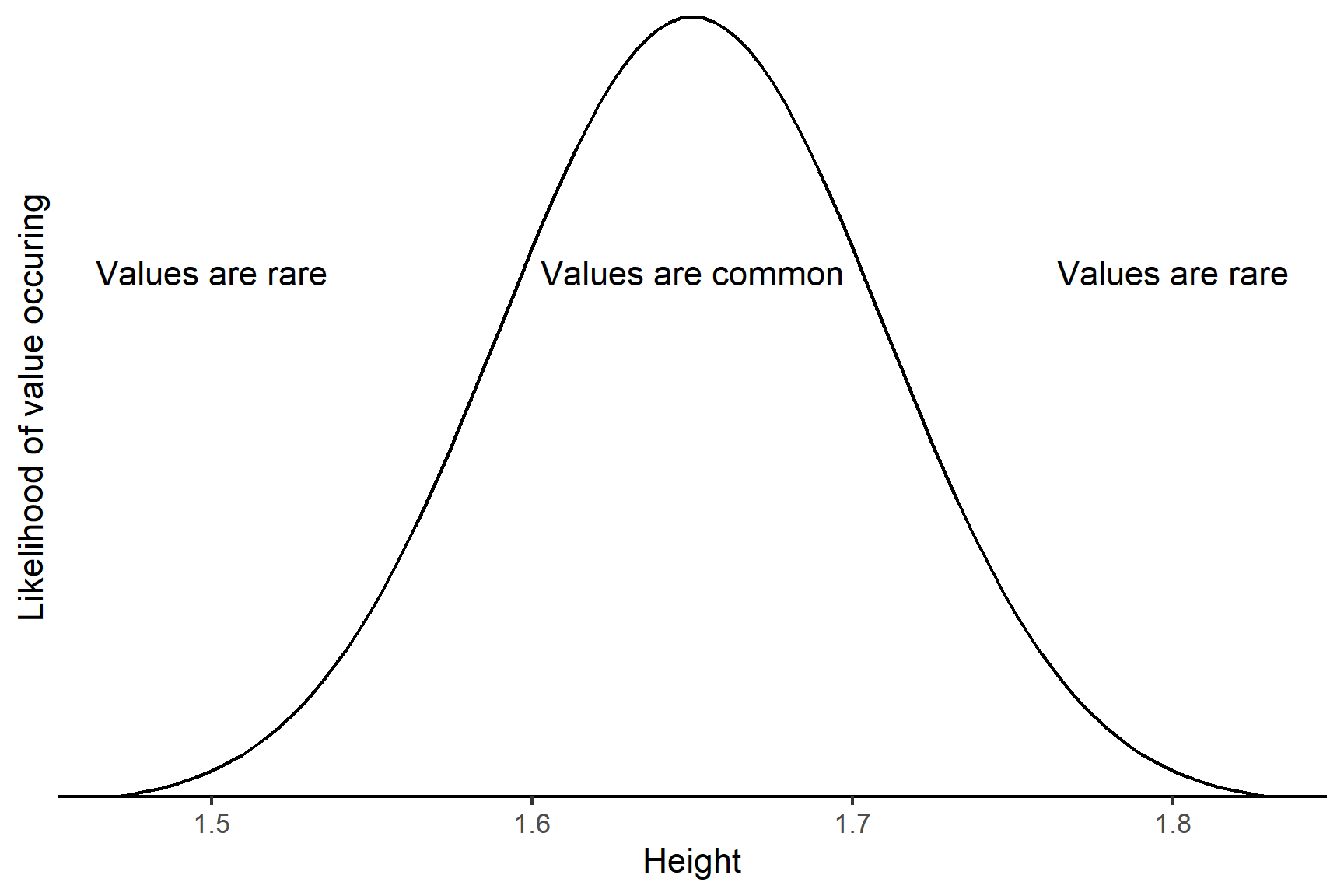
The mean and standard deviation are the best way to summarise a normally distributed variable.
5.7 Theory and practice
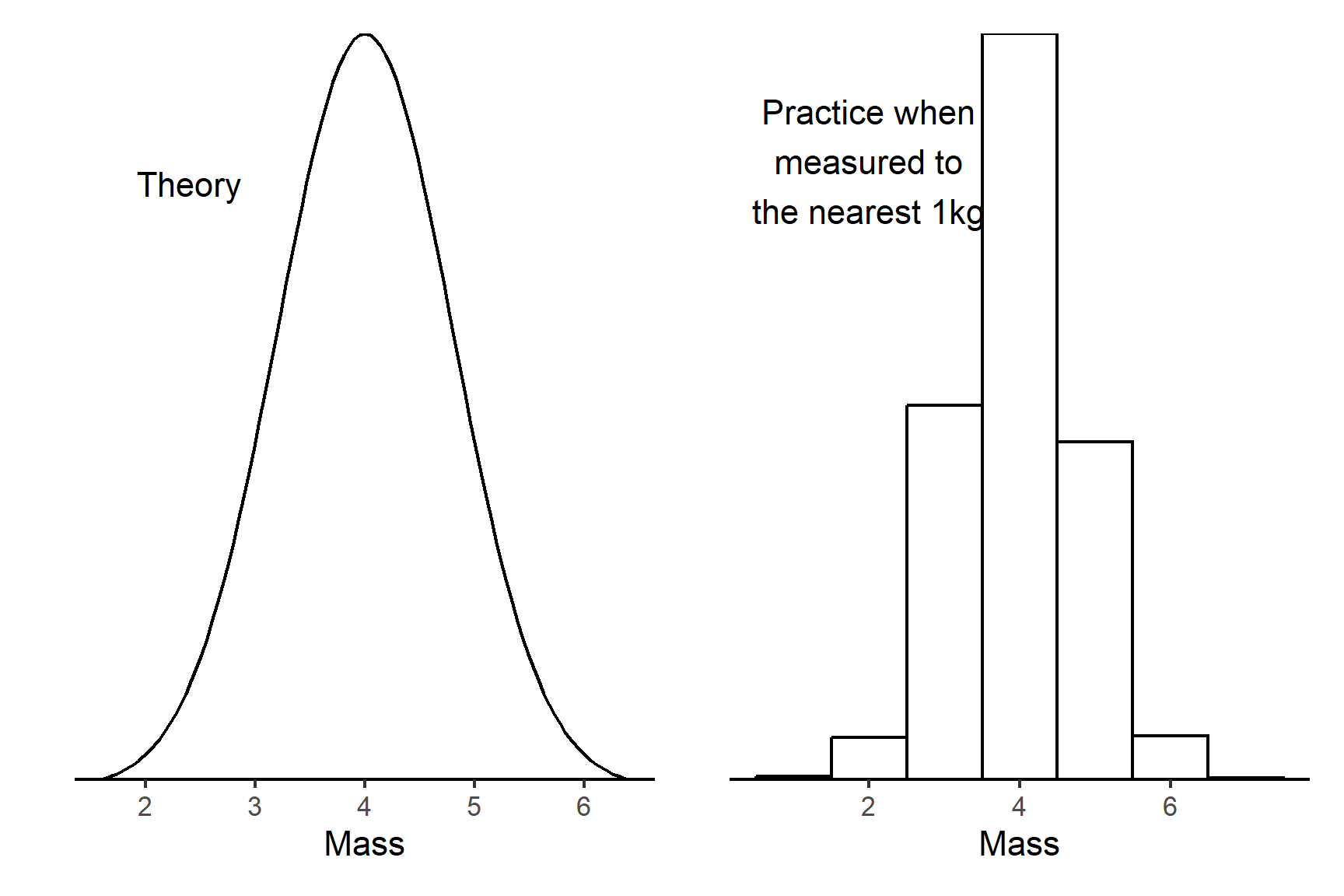
The distinction between continuous and discrete values is clear in theory but in practice, the actual values you have may differ from the expected distribution for a particular variable. For example, we would expect the mass of cats to be continuous because any value in the range is possible. However, if our scales only measure to the nearest kilogram, then the values become discrete because the only the values possible are 0, 1, 2, 3, 4, 5, 6 and 7. The gap between values, 1kg, is big compared to the range of values we expect (Figure 5.6).
In contrast, the number of hairs on a human head ranges from about 80,000 to 150,000 so the difference between having 100,203 hairs and 100,204 hairs is so tiny the variable is practically continuous (Figure 5.7).
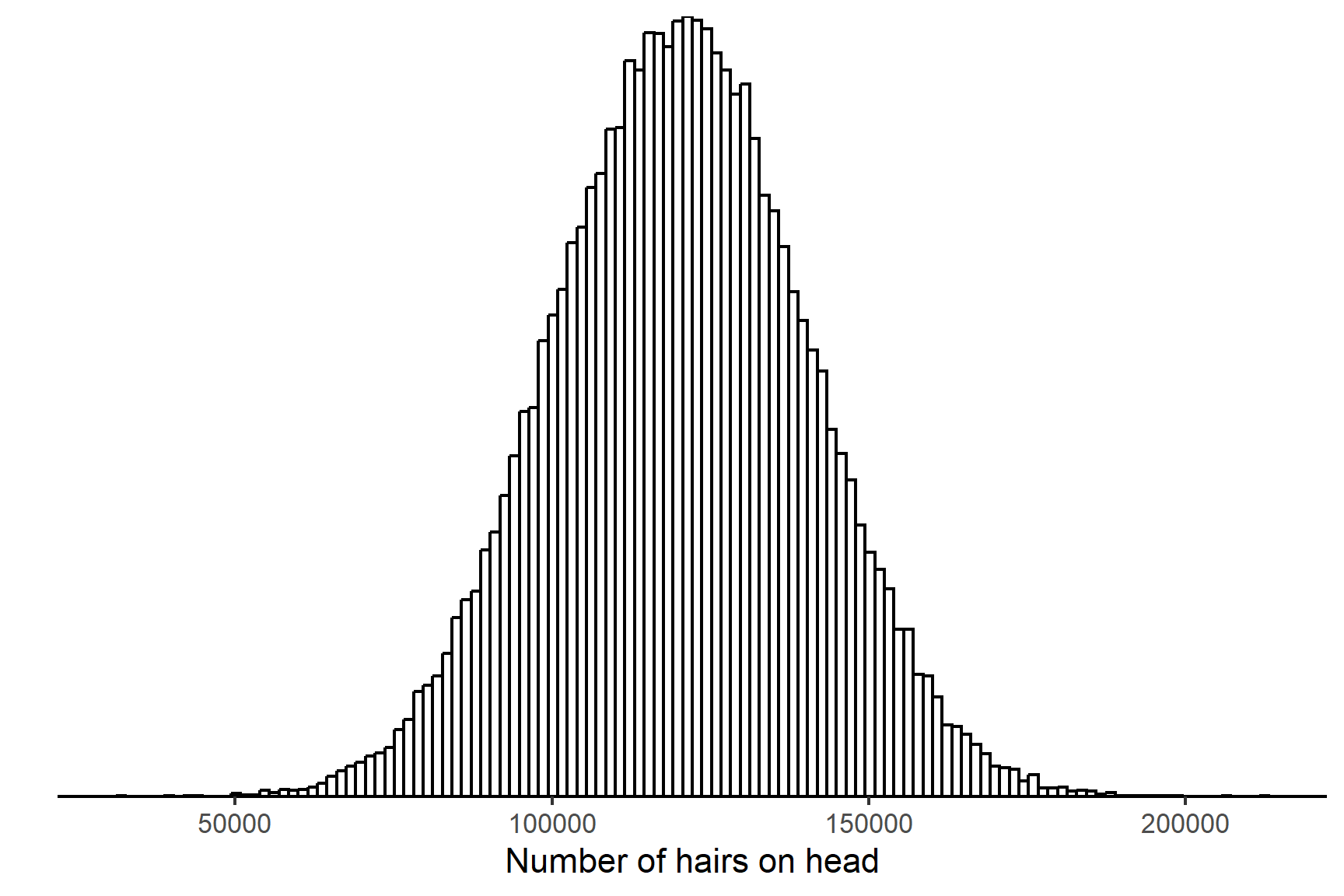
A rule of thumb is that if the mean count is above about 100, then the distribution of counts closely matches the normal distribution.
5.8 Summary
Data: Data consists of variables (properties measured or recorded) and observations (individual things with those properties). Data is commonly organised with variables in columns and observations in rows.
Roles of Variables in Analysis: Variables in research can be independent or explanatory variables (chosen or set by researchers) and dependent or response variables (measured by researchers).
Distributions: A variable’s distribution describes the types of values it can take and the likelihood of each value occurring. Variables can be classified as discrete (specific values) or continuous (any value within a range). The shape of a distribution is determined by parameters.
Discrete Data: Discrete variables can be categories or counts. Categorical data can be nominal (no order) or ordinal (ordered) and are best summarised with the mode or a table. Counts are often best summarised by the median and interquartile range.
Continuous Data: Continuous variables can take any value within a range. The normal distribution is the most common continuous distribution and is best summarised with the mean and standard deviation.
Theory and Practice: While the theoretical distinction between continuous and discrete values is clear, the actual values obtained in practice may deviate from the expected distribution. Measurement precision and range affect whether a variable is considered continuous or discrete. A rule of thumb suggests that if the mean count is above approximately 100, the distribution of counts approximates a normal distribution.
A quadrat is a frame used in ecology to outline a standard unit of area for study of the distribution of plant species over a wider are. Typically, quadrats are placed randomly over the area and the number of individuals in each quadrat is recorded.↩︎